
Why AI Isn't Built for Attribution: Understanding Transformers
“At OpenMercury, we’re exploring how to build AI systems that preserve the chain of knowledge—because understanding where information comes from is as important as the information itself.”
Transformer-based AI models – including large language models like GPT – have revolutionized language generation, but they often struggle with a fundamental concept that humans take for granted: authorship attribution.
These models absorb vast amounts of text (authored by countless individuals) and learn to produce coherent, contextually relevant responses. In doing so, however, they tend to lose track of who said what. As a result, generative AI outputs can echo existing ideas, styles, and even exact wording without providing any trace back to the original authors.
This article explores why this happens, how transformers process context in ways that blur source provenance, and why preserving attribution in such models is inherently difficult. We will also examine concrete examples of attribution failure, review attempts to build systems that do maintain provenance (and their limitations), and discuss the implications for intellectual property, citation norms, scientific credit, and accountability in AI-generated content.
1. How Transformers Use Attention and Context (and Why Information Gets Blended)
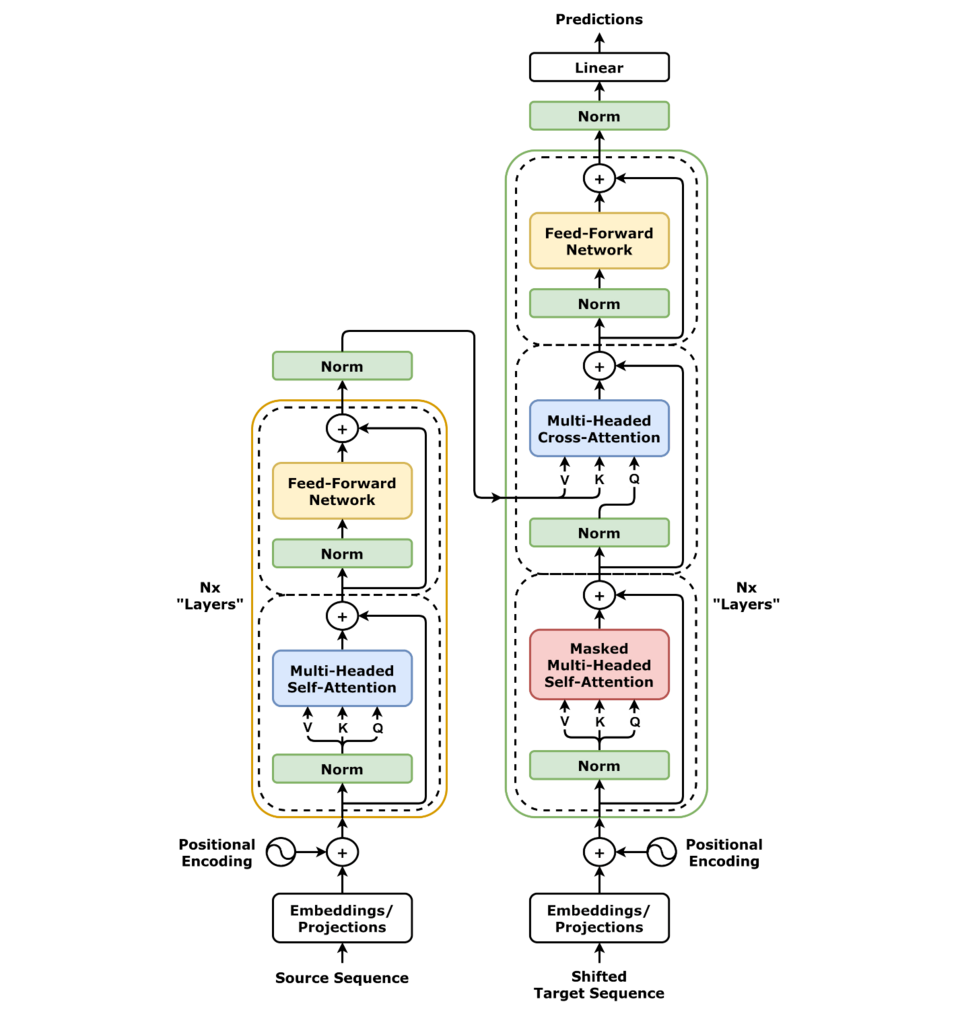
Figure: The transformer architecture (encoder-decoder) with multi-head self-attention (green) as its key component. Each layer allows tokens to attend to (look at) other tokens in the sequence, mixing information from across the input. (source: NIPS'17)
At the core of models like GPT is the transformer architecture, which uses a mechanism called self-attention to process input text. Each piece of text is first broken into tokens (numerical vector representations of words or subwords), and at each layer of the transformer, tokens are “contextualized” with one another via multi-head attention. In simpler terms, the model looks at all the other words in the input to decide how important they are for interpreting a given word, and it adjusts that word’s internal representation accordingly. Key information from relevant words is amplified, while less pertinent context is downplayed . This means that each output token is essentially a blend – a weighted combination – of many input tokens, computed by summing over the inputs with learned attention weights.
Because attention creates these weighted combinations of the entire context, the transformer’s understanding of any given word or sentence no longer remains isolated to a single source or speaker. For example, consider a sentence: “Alice said X. Bob replied Y.” A transformer processing this may attend to X when interpreting Y, and vice versa, effectively entangling the content from Alice and Bob. Through training, the model learns statistical associations between words and phrases, but not any persistent identifier of which entity or document those words came from. The architecture is extremely powerful for capturing meaning – it can resolve pronoun references and long-range dependencies by pulling in clues from anywhere in the text . However, this power comes at the cost of erasing the boundaries of provenance. Once information has been absorbed and represented in the model’s internal vectors, it’s treated as part of a shared context, not as a quote from a specific source.
To illustrate, researchers often visualize attention patterns to show how context is mixed. In a famous example, given the sentence “The animal didn’t cross the street because it was too tired,” a transformer model attends strongly from the pronoun “it” to the noun “animal” – inferring that “it” = “the animal” . The model “blends” the representation of “it” with information from “animal” to clarify meaning. This solves a comprehension problem, but notice what else happened: the specific contribution of “animal” is now fused into the network’s representation of “it.” If we were tracking which word came from where (say, which document or speaker), that information is not preserved in any dedicated field – it’s folded into the pattern of activations. The attention mechanism doesn’t discriminate by source, only by content relevance.
Through many layers of transformers, such blending and abstraction away from surface details only increases. By the time a model is generating a response, it has distilled all relevant context into a unified representation used to predict the next word. There is no slot in that process for “and the source of this fact is…” – unless explicitly built into the prompting or architecture. The transformer’s goal is to produce likely continuations of text, not to cross-reference or cite. As The Atlantic put it, “large language models are designed to write fluent prose by predicting words in sequence, not to cross-reference information or create citations” . In essence, transformers do not inherently know or remember where a piece of information came from – they only know how likely it is to follow from the context.
2. Why Authorship and Source Get Lost in Training and Inference
The loss of attribution isn’t just a quirk of inference (generation); it begins in the training phase. During training, a language model ingests terabytes of text from the internet, books, articles, etc., and optimizes to predict the next token in every example. Crucially, during this process the model does not store metadata about sources or authorship – it’s simply adjusting billions of weights to increase the probability of outputting sequences that mirror the patterns in the data. As one expert succinctly noted, “at training time, language models don’t keep track of the sources” . All the knowledge is baked into model parameters in a distributed fashion. If two different sources express the same fact (“Water boils at 100°C” in a chemistry textbook, and “100°C is the boiling point of water” in a cooking blog), the model will recognize that pattern and likely reproduce it when asked about boiling water. What it won’t have is a retrievable memory of which source each phrasing came from. The training objective doesn’t require it to – it only requires that the model’s output sounds plausible and contextually appropriate. In fact, the moment a language model starts generating text, any explicit link to its training sources is essentially gone. The model is composing a new sequence based on probabilistic influence of countless prior texts, not quoting from a single identifiable document.
Figure: Authorship Tags Lost in the Funnel — Training abstracts away source identity into distributed parameters.
It’s important to realize that large language models do not have a built-in concept of “who said this” or “where did this fact come from.” They represent language as patterns, not as entries in a database with source annotations. Even when a model outputs a well-known quote or a specific piece of trivia, it’s doing so because that sequence of words was statistically likely given the prompt, not because it deliberately looked up the source. There have been striking examples of this in practice. Researchers have found that if you prompt GPT-style models cleverly, they might emit a passage that appears in their training data – for instance, a paragraph from an old academic paper or a piece of software documentation – almost verbatim. When this happens, the model typically fails to provide any citation or indication of where the text originated. In one scenario, a user working on a scholarly essay got a well-written paragraph from an AI assistant, not realizing it closely paraphrased an obscure 1975 paper by someone else. The LLM had likely seen that paper during training, “yet it [was] not able to reverse-engineer its own paragraph or accurately trace it back to its source” . The idea was reproduced without credit, creating a risk of unintentional plagiarism.

This effect isn’t malicious – the AI isn’t trying to hide the source; it truly does not know the source in any human-like sense. The training has abstracted away “Smith (1975) said X” into just “X is a valid and well-formed statement in context Y.” Similarly, in multi-turn conversations or dialogues, a transformer model can easily get confused about which speaker provided which piece of information. Without special handling, it might blend the persona of two speakers or use a statement from one speaker as if the other had said it. For example, in summarizing a chat between Alice and Bob, a naive language model might incorrectly attribute a quote to Alice that Bob actually said. This is a common failure mode observed in dialogue summarization tasks – misattributed quotes – because the model picks up on content but doesn’t solidly track the speaker tags. The model’s attention may focus on what was said rather than who said it, especially if pronouns or conversational context make it ambiguous.

Figure: An example attention visualization (from an English-to-French translation model) focusing on the word “it” in the sentence “The animal didn’t cross the street because it was too tired.” The model’s attention (lines) connects “it” primarily to “animal,” effectively baking the context of “animal” into the representation of “it”. While this improves understanding, it demonstrates how information from one part of the text is blended into another – with no mechanism to label where that information originally came from. (source: Google Research)
Hallucinated or misplaced attributions are another manifestation. An AI might generate a sentence like “As Albert Einstein famously said, Genius is 1% talent and 99% hard work.” – a confident attribution, except Einstein never actually said that (it’s often misattributed to him by humans too). The model isn’t intentionally lying; it has seen patterns of quotes and attributions and is mimicking them. Because it does not have grounded knowledge of sources, it may end up pairing a quote with a prominent name that commonly co-occurs with quotations. In journalism and research contexts, this tendency can be troublesome. A 2023 newsroom experiment noted that “LLMs can potentially make up quotes or misattribute accurate quotes to the wrong sources” due to the way they mimic learned patterns by predicting likely words . In fact, they found that ChatGPT would frequently rewrite or alter direct quotations, even when explicitly instructed not to, and sometimes attribute statements to the wrong person . This unpredictability in preserving “who said what” stems directly from the model’s training objective – it was never trained to keep attributions separate, only to produce fluent text.
It bears emphasizing that transformers have no native representation for “author” or “source”. Unlike a structured database or a knowledge graph that might store facts in triples like (source, claim), a transformer just stores probabilities of sequences. Without special architecture, there’s no internal tag that says “this token came from Wikipedia” or “this sentence was originally written by Shakespeare.” Unless such tags are introduced as part of the input data (and models can be trained with special tokens indicating sources or speakers, but this is not common in broad pretraining), the model’s hidden states and outputs contain no explicit provenance metadata. As an academic commentary succinctly put it, ChatGPT is incapable of citing anything correctly, at least in the normal way we think of citation and attribution – it “doesn’t handle facts and sources like a person” . It will cheerfully generate a bibliography if asked, but often those references are fabricated, because it’s just following the form of a citation without accessing a truth-conditioned source. The transformer architecture by itself has no mechanism to verify a source; it has essentially blurred all its sources into one mass of “knowledge” during training.
3. Concrete Examples of Attribution Failures in Practice
To ground this discussion, let’s look at a few concrete examples where transformer-based models blurred or lost authorship information:
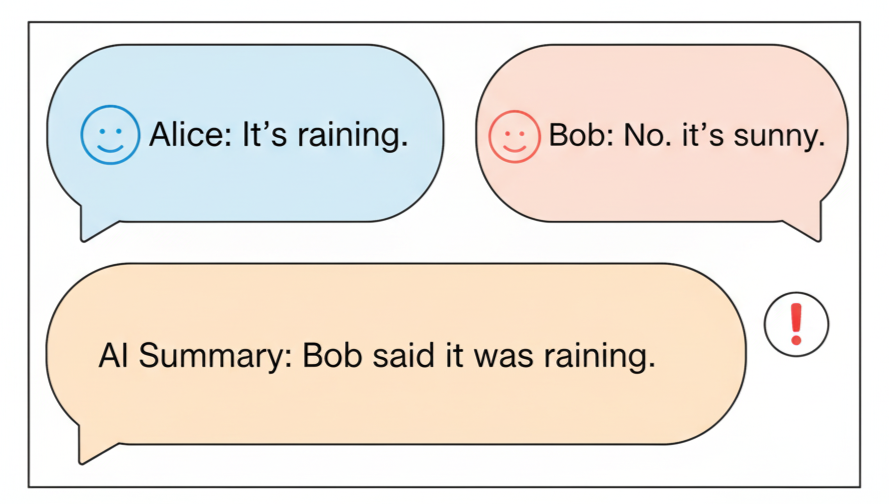
Figure: Who Said It? Dialogue between Alice and Bob is summarized incorrectly by an AI bubble — a visual metaphor for quote misattribution.

Figure: The Confident Hallucination. AI confidently types realistic citations — some real, some fabricated — illustrating how form replaces verification.
Academic Writing Assistance: Consider a researcher using an LLM to help draft a literature review. The user prompts the model with a summary of an idea, and the model expands it into a well-phrased paragraph. Unbeknownst to either, the model’s output closely mirrors specific lines from a paper the researcher has never read. Because the model didn’t cite anything (and wasn’t asked to), the researcher might incorporate those lines thinking they’re just well-worded elaborations of their own thought. In reality, they are effectively unattributed quotes from someone else’s paper. This scenario has raised ethical flags in academia: “If an AI system reproduces insights from an obscure 1975 paper without citation, does this constitute plagiarism?” and even without intent to deceive, the human user “benefits from the uncredited intellectual contributions of others.” This is a novel kind of “attributional harm”. The provenance chain is broken – neither the model nor the user gives credit to the original author, because the origin is effectively invisible.
Misattributed Quotes in News Summaries: Journalists have experimented with GPT-4 for summarizing interviews or articles. One problem that arose was the model altering quotes or attributing them to the wrong person. In one trial, ChatGPT was asked to summarize a news article and instructed to keep all quotes unchanged. Instead, it often paraphrased the quotes or changed who said them . For example, if the article stated Alice said “It’s raining.” Bob later contradicted Alice.”, the model might output something like: Bob said it was raining, which Alice later contradicted. – completely flipping the attribution. Such errors occur because the model is guided to produce a coherent summary; it doesn’t have an internal safeguard that locks a quote to a speaker. The words of Alice and Bob exist in its representation, but who uttered those words can slip during rephrasing. Quote-aware summarization is an active area of research now, precisely to combat this tendency of LLMs to mix voices .
Fabricated Citations and Sources: Perhaps the most infamous examples are when LLMs produce entirely fake citations. Lawyers, students, and researchers have been duped by confident references generated by AI that turned out not to exist. For instance, an attorney once asked ChatGPT for cases supporting a legal argument; the model output a list of court case citations that were completely made-up, but formatted plausibly. Why does this happen? Because the model knows what a citation looks like but doesn’t actually retrieve data from a law database. It mashed up common legal terminology and names into a fictitious source. This underscores that the model has no built-in database of true references – when pressed for a source, it fabricates one based on patterns. A study in 2023 found that even top-tier models often failed to provide correct or complete citations more than half the time when answering knowledge questions . They would either omit the source or point to a tangential or incorrect source. The consistency and reliability of attribution were very low. Only by integrating external tools (like a search engine) did some systems (e.g. Bing’s AI chat or Perplexity.ai) manage to include citations – and even then, the AI sometimes cited secondary sources or mirrors of content instead of the original, because it wasn’t truly understanding provenance, just linking to something that had similar text.
These examples highlight a common theme: without special design, an LLM treats content without ownership. It will remix, rephrase, and regurgitate training data in novel ways, but it won’t say “According to X…” unless prompted to mimic that style – and even then, as we saw, it may not get X right. It doesn’t intentionally “steal” credit; it operates with no concept of credit. And this is a direct consequence of how transformers generalize language.
4. Attempts to Preserve or Recover Attribution in AI Systems
Given the stakes – from academic integrity to journalistic accuracy and intellectual property – researchers and developers are actively exploring ways to inject a notion of provenance into AI-generated content. Several approaches have been tried, each with its own trade-offs:
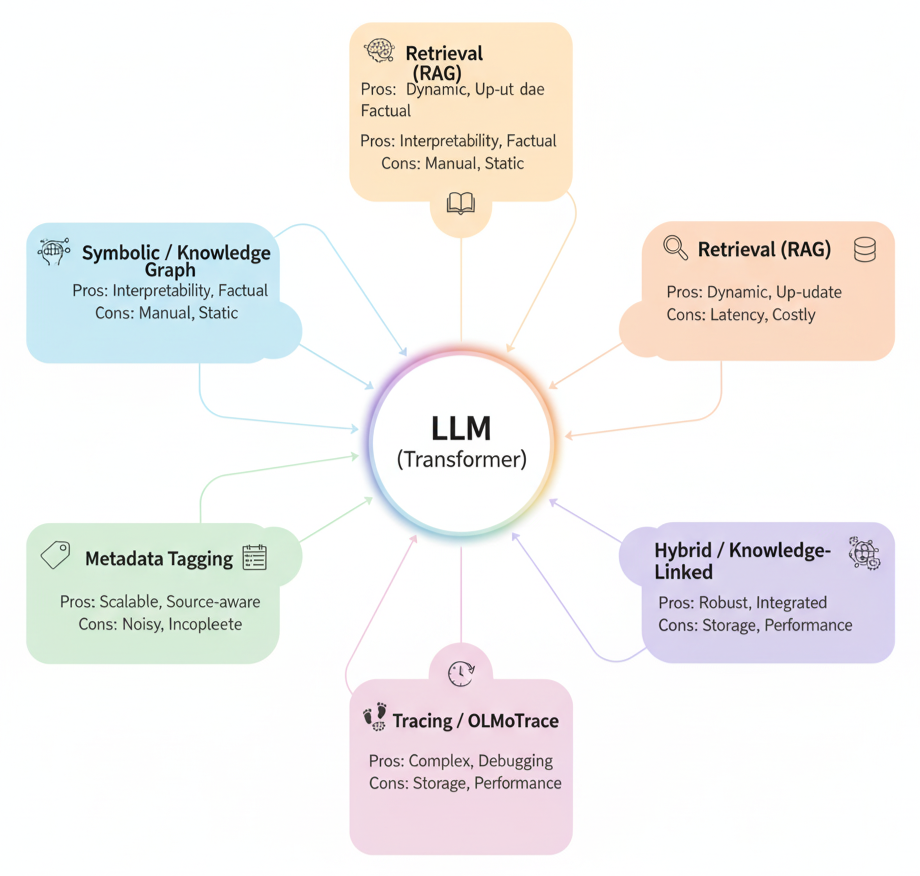
Figure: Partial Fixes for Attribution — Current research directions for restoring provenance.
Symbolic or Knowledge-Based Systems: Before the deep learning revolution, AI systems often relied on knowledge bases or rules. In those systems, facts could be stored with explicit attribution (e.g., a knowledge graph might have a record that “Boiling point of water = 100°C (source: CRC Handbook)”). Some modern approaches seek to combine this symbolic paradigm with neural networks. For example, a system might use a knowledge graph of scientific findings where every entry has a source, and the language model is constrained to generate text consistent with that graph. This would allow it to cite the source for each fact because it’s built into the data. The limitation, however, is that symbolic databases are never as comprehensive or flexible as what a fully trained transformer knows. Maintaining a knowledge base with all possible facts (and keeping it updated) is a herculean effort. Also, if the model has both a neural and a symbolic component, it adds complexity: the model might still default to its learned neural “knowledge” if not carefully controlled. Symbolic AI can guarantee provenance at the cost of coverage – you only get attribution for what you’ve explicitly catalogued. It’s great for narrow domains (e.g., medical expert systems that always cite medical literature), but scaling it to all of Wikipedia-level knowledge (and beyond) is challenging.
Retrieval-Augmented Generation (RAG): One promising framework used in practice is to have the model retrieve relevant documents at query time and base its answer on them. For instance, systems like OpenAI’s WebGPT, DeepMind’s RETRO, or Meta’s Fusion-in-Decoder will, given a question, perform a search (on a document index or the web), bring back say 3 relevant passages, and then the model generates its answer conditioned on those passages. The answer can then directly quote or reference these retrieved texts, effectively providing sources in-line or via footnotes. If you’ve used the Bing AI chat or Perplexity.ai, you’ll notice they cite sources for each sentence – that’s retrieval augmentation in action. This approach leverages transformers for language fluency and reasoning, but grounds their output in external knowledge that comes with citations. It’s a bit like a student who is taught to always look up facts in an encyclopedia and quote the entry. The benefit is clearly that the user can verify and trace claims. However, RAG systems have limitations: they depend on the retrieval component finding the right information (if the search fails or brings back flawed sources, the output will suffer). They also can only cite what they retrieve – which is usually limited to relatively short contexts. If a question spans multiple pieces of knowledge or some context not easily searchable, the model might still hallucinate connections. Moreover, RAG doesn’t solve authorship for style or idea attribution – it helps with factual provenance (where did this fact come from) but not necessarily “whose writing style am I imitating.” The transformer could still generate text in the style of a particular author without saying who inspired that style, since retrieval is typically focused on substantive content.
Metadata Tagging and Prompt Engineering: Another approach is to explicitly feed source information into the model’s input or prompt. For example, one could format training data or prompts with annotations like: [Author: Alice] Hello, how are you? [Author: Bob] I'm fine, thanks. in hopes that the model will learn to maintain these tags. In multi-turn chatbot settings, we do see a simplified version of this – for instance, ChatGPT is internally prompted with role indicators (“User: … Assistant: …”) to keep track of who is speaking. This helps maintain conversational attribution to some extent. But when it comes to broader provenance (like tracking which website or book a piece of information came from), simple metadata tokens often aren’t enough. If not rigorously enforced, the model might ignore or lose them in longer outputs. One intriguing idea is to have the model output structured provenance info as part of its answer – e.g., JSON metadata or invisible markers in the text. Indeed, some have suggested that AI systems be built to embed details about their inputs and influences within the content they generate, via metadata tags or structured data . For example, an AI-generated image might carry an invisible watermark identifying the model and dataset; analogously, an AI-generated text could carry hidden markers indicating which sources were most influential. However, these require changes to either the model architecture or the output format that are not standard. And if the provenance data is not exposed to end users in an accessible way (or platforms strip it out), it doesn’t help accountability. So while metadata tagging is conceptually straightforward, in practice it’s only as good as the ecosystem that preserves and respects it .
Knowledge Graph and Hybrid Models: A variant of symbolic and retrieval methods involves linking the language model to a knowledge graph or database at training or inference time. For instance, a hybrid model might, as it generates text, dynamically query a database of known facts (with citations) to fill in details. If asked “Who discovered penicillin?”, the model could query a fact store that says “Penicillin – discovered by Alexander Fleming (source: biography.com)” and then respond with that information and perhaps even add the citation. Projects like Wikipedia’s integration with language models, or work on KILT (Knowledge Intensive Language Tasks), aim to ensure that models can point to supporting documentation. Still, these systems face the alignment problem: the model has to decide when to trust the external knowledge source versus its own learned parameters. They also inherit all the issues of maintaining a high-quality knowledge graph. While they can improve factual accuracy and source citation, they don’t fully address attribution of phrasing or ideas. If a model generates a stylistic pastiche of Ernest Hemingway, a knowledge graph won’t necessarily flag “by the way, this style is inspired by Hemingway” – because style attribution is not a discrete fact in a database.
Tracing Model Outputs to Training Data: A very recent line of research tries to retrofit transparency onto trained models. For example, the OLMoTrace system (from a 2025 study) attempts to trace the outputs of an LLM back to specific examples in its training data . Essentially, when the model generates a sentence, OLMoTrace searches through the training dataset (which might be trillions of tokens) to find passages that closely match the output. If it finds, say, a verbatim match or a very similar phrasing in the training corpus, it can surface that and say “this response likely came from this source.” This is like giving the AI a bibliography after the fact. Such a system demonstrated that it “can pinpoint exact matches between what a model says and the documents it learned from”, turning the black box into something more verifiable . In an interactive setup, one could imagine asking a model for an answer and then clicking a button to see snippets of its training data that led to that answer . This is a powerful concept for transparency. However, it’s still in early stages of research. It also inherits a couple of limitations: if the model’s output is a synthesis of many sources (not a verbatim quote), tracing it becomes fuzzy – you might get several partial matches rather than one clear source. And if the training data is proprietary or not disclosed, there are ethical and practical issues with revealing it (privacy, security, etc.). Nonetheless, systems like OLMoTrace represent an important acknowledgement that users need ways to audit where AI outputs come from, even if the model itself isn’t internally tracking it.
Each of these approaches – symbolic, retrieval, metadata, hybrid, tracing – provides pieces of a puzzle. Yet none is a silver bullet. They often work well in constrained environments or for specific use cases, but preserving authorship across the full breadth of what a model like GPT-4 can do remains unsolved. Indeed, several experts have suggested that AI models might never be perfect at finding and citing information, at least not without fundamentally new architectures or constraints. The transformer paradigm, as powerful as it is, was not originally designed with attribution in mind, so we’re effectively bolting on solutions after the fact.
5. Why It’s Inherently Hard to Maintain Provenance in General-Purpose Transformers
Considering all of the above, we can argue that preserving authorship and provenance in a general-purpose transformer is inherently difficult due to a combination of factors:
Figure: Unmixing the Cake — Distributed learning makes source disentanglement nearly impossible.
Distributed Knowledge Storage: Transformers store knowledge in millions of parameters in a distributed way. There’s no modular separation like “knowledge from book A lives in these neurons, knowledge from website B in those neurons.” It’s all superimposed via training. This makes disentangling sources extremely hard – analogous to trying to un-mix the ingredients after baking a cake. The model doesn’t have a pointer to where each piece of information came from.
Generalization Over Memorization: We actually want models to generalize – that’s what makes them powerful. If the model simply memorized entire documents and regurgitated them with citations, it would be less useful (and ironically, easier to attribute!). Instead, models abstract and synthesize: they take ideas from many places and fuse them into a new sentence. While great for creativity and answering complex prompts, this behavior means that an output might be a mosaic of dozens of influences. How do you assign credit in such cases? Perhaps every word has a different source influence. The model has effectively created something new out of old pieces, and teasing apart those pieces is non-trivial.
Context Window Limitations: Models have a fixed context window for inputs (e.g., 4,000 tokens or now even 100,000 tokens in some). Within that window, if we explicitly label sources (like providing a document excerpt and citing it), the model can keep track of it for that one interaction. But it cannot consider all training sources simultaneously – only what fits in the prompt. So we rely on retrieval or user-provided citations for attributions in the input. Anything outside the window is just in the model’s memory without labels. As the conversation or generated text grows, even if sources were given initially, they might scroll out of the context window and thus out of the model’s “mind” for that generation. The attention mechanism doesn’t reach beyond the set context length, meaning provenance information can literally drop away if it was provided too many tokens ago.
No Reward for Attribution (Currently): The model’s training objective does not reward it for citing sources or maintaining speaker identity unless it was explicitly part of the training data. In fact, most training corpora do not have “Alice said: … Bob said: …” labels in a consistent way (except dialogues, which are a small subset), nor do they have Wikipedia-style citations after each sentence. Therefore, the model never learned the concept of staying true to a source reference, because it wasn’t asked to. Efforts like reinforcement learning from human feedback (RLHF) have focused on correctness and harmlessness, but not so much on attribution fidelity. Until we build attribution as a criterion (e.g., penalize the model when it hallucinates a citation or misattributes a quote), the model has no internal incentive to improve on this front.
Scale and Domain Breadth: Transformers like GPT-4 are trained on virtually the entirety of public written knowledge. This spans countless authors, styles, and domains. Any attempt to maintain authorship would need to scale across all those domains. Maybe one could, in theory, tag every sentence in the training data with an author ID or source ID and train the model to predict those as well. But aside from being practically unfeasible (imagine tagging billions of web pages with author info, which is often unavailable or ambiguous), the model capacity might then be overwhelmed by trying to memorize those tags. And what about combined knowledge? If a model’s answer is influenced by two sources, would it list both? Current models can’t even know that two sources were involved, because they only see the blended result in their weights.
Dynamic Knowledge and Updates: Authorship tracking is further complicated when models are updated or fine-tuned on new data. For example, after initial training, a model might be fine-tuned on conversation data where it’s taught to speak in a certain style or follow certain policies (like the ChatGPT “assistant style”). This can override some of its direct memorization of sources (if any). The “voice” of the model becomes a mixture of the fine-tuning instructions and pretraining data. In such cases, even identifying which parts of the output come from pretraining vs. fine-tuning is difficult, let alone attributing pretraining parts to specific sources.
All these reasons converge to a reality: in the general case, asking a vanilla transformer model to preserve a clear chain of attribution is like asking a novelist to footnote every sentence of their novel with all sources of inspiration. It’s arguably against the nature of the creative generalization process. The model “writes” in its own learned voice, which is a statistical amalgam of everything it read, not a transparent collage.
6. Implications for Intellectual Property, Citation, and Accountability
The fact that transformers blur authorship lines is not just a technical quirk; it carries significant implications:
Intellectual Property (IP) and Ownership: Artists, writers, and developers have voiced concern that AI models trained on their works may produce output that derives from those works without credit or compensation. For instance, an AI model might generate an image or a piece of music in the style of a particular artist. The artist’s signature style was part of the training data and is now reproduced with zero acknowledgement. This raises the question: if the output is very similar to a known piece (or could even be seen as a derivative work), who owns it? The human user? The model’s creator? The original artist? Currently, the legal system is grappling with these questions, and there’s a growing call for transparency. If models could at least say “this output was influenced by artist X’s style,” it would help in assigning credit (or flagging potential infringement). But as we’ve discussed, the models won’t do this by themselves. Some proposals suggest mechanisms like collective licensing or compensation – where AI developers pay into a fund for the use of copyrighted training data – as a rough proxy for attribution . However, that still doesn’t inform a consumer viewing the content who originally inspired it. Without technical means to trace influences, enforcing IP rights or even moral rights (the right to be credited) becomes very murky.

Figure: The Broken Chain of Credit — When attribution disappears, credit and accountability follow.
Citation and Scientific Credit: In scientific writing and academia, giving credit via citations is foundational. If AI assistance in writing becomes common (as it already is in some areas), there is a real risk that significant ideas will circulate without recognition of their originators . For example, a language model might suggest a solution to a problem that was actually published in a paper a decade ago. If the researcher using the AI isn’t aware of that paper, they might present the solution as if it were novel. This breaks the chain of scholarly credit and can mislead the community about who discovered what. It also deprives the original authors of citations that factor into their reputation and career. Some journals and conferences are already formulating policies around AI-generated text, precisely because of these concerns. If a large language model contributes to a section of a paper, how do we ensure the sources of its statements are verified and cited? One approach is requiring authors to personally vet and provide references for any factual claims, regardless of whether they came from AI. Another is to treat the AI as a tool and not as an author – meaning the human takes full responsibility for the content. In any case, the lack of built-in citation from the AI is adding workload: users must double-check and find sources after the fact, or risk unknowingly plagiarizing. It’s a new kind of diligence that wasn’t needed when all writing was done by humans who knew exactly which sources they were drawing from.
Accountability and Misinformation: When an AI system produces a false or defamatory statement, the question of accountability arises. If a model states, “Company X’s product causes cancer,” and this is baseless, who is accountable? The model can’t be sued; it’s not a legal entity. Is it the company that made the model, the deployer of the system, or the user who prompted it? One aspect of accountability is being able to trace where the model might have gotten that idea – was it in the training data (perhaps some forum post with misinformation) or was it a conflation the model made? Without provenance, it’s hard to even correct the issue. If we knew the model was referencing a specific training document, one could at least flag that source as unreliable in the future. But with end-to-end trained transformers, we don’t have a log or explanation for most outputs. This opacity makes it difficult to debug misinformation. It also means that victims of AI-generated falsehoods (like someone whose quote was fabricated or whose position was misrepresented) have no straightforward way to find out how or why the AI said that. This has led to calls for AI systems that can provide “show your work” style evidence for their claims, as a step towards accountability. Researchers are striving for models that, for instance, can not only answer a question but also provide the passage from Wikipedia that supports the answer. As we discussed, retrieval-augmented methods are one way to do that. Additionally, some efforts like watermarking are looking to at least mark content that is AI-generated (though not its sources), which helps on a metadata level to know who to blame (the AI) but not where the AI got its info.
Erosion of Trust: In fields like journalism, if AI is used to draft content, maintaining trust requires that quotes and facts are accurate and correctly attributed. If a news outlet publishes AI-assisted articles that later turn out to contain misattributed quotes or uncited information taken from a competitor’s scoop, it could seriously undermine credibility (we’ve already seen some newsrooms have incidents of AI-written pieces with errors, leading to backlash). The inability of current AI to consistently attribute sources is a big reason many editors are cautious. The Atlantic article observed that even when AI systems tried to cite sources, they often cited the wrong source (like a secondary aggregator rather than the original reporter), which mirrors issues already present in human-run aggregation but could be amplified . If left unchecked, this can contribute to a media ecosystem where originators are increasingly hidden and derivative summaries or misinformation spreads more easily.
In summary, the blending of authorship in transformer models creates a tension: we want AI to be broadly knowledgeable and creative, but we also need it to respect the origin of that knowledge. Solving this will likely require not just technical innovation, but also social, legal, and educational adaptations.
7. Conclusion: Toward Transparent and Accountable AI-Generated Content
Transformer-based models have undeniably altered the landscape of content creation, enabling fluid auto-completion of emails, lifelike dialogue agents, and rapid information synthesis. Yet, as we have explored, these models by default operate like brilliant mimics with amnesia for where they learned everything. They excel at generating language, but are oblivious to the chain of provenance behind that language . This presents new challenges for how we think about authorship, credit, and responsibility.
We’ve seen that introducing robust attribution into transformers is non-trivial – it often feels like forcing a square peg into a round hole. Nonetheless, the importance of doing so is growing by the day. The research community is actively searching for ways to make AI outputs more traceable, whether through hybrid systems, improved training regimes that include attribution, or post-hoc analysis tools. In parallel, there are calls for norms and possibly regulations to ensure transparency about AI involvement in content creation. For example, some have suggested that any AI-generated text should come with a disclosure or even a log of sources used. This might eventually become a standard: imagine reading a generated article where each claim is hyperlinked to a source, just as Wikipedia pages are – except the AI would be doing it for all content it produces.

Figure: From Black Box to Glass Box — The future of AI: from opaque synthesis to transparent citation. Left: opaque black AI cube outputting “unknown source”. Right: transparent cube with visible source icons and citations.
Until such solutions mature, we operate in a kind of “gray zone” where human oversight is essential. Users of language models must practice AI literacy: knowing that the beautiful paragraph just produced might contain a mix of truths and borrowed ideas that need verification. Educators and institutions are emphasizing the need to double-check facts and add citations after an AI draft is generated. Some publications have even banned unsourced AI content, precisely because of the provenance problem.
The broader implication is a re-examination of our notions of authorship. When a human writes a text, we assume that human is the author (or has cited others). With AI in the loop, authorship becomes a more collective concept – the human, the model, and implicitly all the humans whose data trained the model are involved. As generative AI becomes woven into creative workflows, we must find ways to keep the links between creators and creations visible . If we fail to do so, we risk a future where significant ideas and works float around untethered to those who birthed them, undermining the very fabric of how we reward creativity and truth.
In closing, solving attribution in AI is not just about credit – it’s about integrity. An AI that can tell you exactly why it said something and where it came from would be far more trustworthy and useful than one that speaks as an all-knowing oracle. Getting there may require new innovations beyond today’s transformers, or hybrids that combine neural and symbolic reasoning. It will also require continued pressure and demand from society for AI that respects and acknowledges provenance. The provenance problem is now clearly recognized, and while it may not have an easy fix, it represents a critical frontier for making AI a responsible and reliable partner in our information ecosystem.
To keep the chain of knowledge intact – a task that, for now, remains in human hands.
References
Agrawal, A., Mackey, L., & Kalai, A. T. (2023). Do language models know when they're hallucinating references? arXiv preprint arXiv:2305.18248. https://arxiv.org/abs/2305.18248
Çelikok, M. M. (2023). Attribution problem of generative AI: A view from US copyright law. Journal of Intellectual Property Law & Practice, 18(11), 796–803. https://doi.org/10.1093/jiplp/jpy082
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., & Liu, T. (2023). A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232. https://arxiv.org/abs/2311.05232
Kalai, A. T., Nachum, O., Vempala, S. S., & Zhang, E. (2025). Why language models hallucinate. arXiv preprint arXiv:2509.04664. https://arxiv.org/abs/2509.04664
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (Vol. 33, pp. 9459–9474). https://arxiv.org/abs/2005.11401
Liu, J., Blanton, T., Elazar, Y., Min, S., Chen, Y., Chheda-Kothary, A., Tran, H., Soldaini, L., Ravichander, A., Authur, J., Muennighoff, N., Schwenk, D., Xie, S. M., Walsh, P., Groeneveld, D., Bhagia, A., Wadden, D., Lo, K., Soldaini, L., ... Farhadi, A. (2025). OLMoTrace: Tracing language model outputs back to trillions of training tokens. arXiv preprint arXiv:2504.07096. https://arxiv.org/abs/2504.07096
Longpre, S., Mahari, R., Chen, A., Obeng-Marnu, N., Sileo, D., Mccoy, W., Muckatira, S., Nagireddy, N., Blagoj, V., Alic, A., Lam, B., Anderson, H., Zong, Y., Park, J. S., Hooker, S., Kabbara, J., Pentland, A., Barak, B., Frankle, J., ... Muennighoff, N. (2024). A large-scale audit of dataset licensing and attribution in AI. Nature Machine Intelligence, 6(9), 975–987. https://doi.org/10.1038/s42256-024-00878-8
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems (Vol. 30). https://arxiv.org/abs/1706.03762
Xu, Z., Jain, S., & Kankanhalli, M. (2024). Hallucination is inevitable: An innate limitation of large language models. arXiv preprint arXiv:2401.11817. https://arxiv.org/abs/2401.11817
Suggested Citation
For attribution in academic contexts, please cite this work as:
Liao, S. (2025). Why AI Isn't Built for Attribution: Understanding Transformers. OpenMercury Research.